The Definition Facility is used to build and change the major objects of ACCENT R. Within the Definition Facility, there are two categories, each of which performs an important function.
The CREATE command names and assign disk files for Data Base Libraries (DBL), Data Sets (DS), and System Files (SF). They also associate each DS with the Schema Definition (SD) that describes the format for its data storage. The CREATE command can be used to attach an existing data file to a DS and make it accessible as an ACCENT R Data Set. Existing System Files can be cataloged in an ACCENT R DBL by an option of the CREATE command.
The DEFINE and MODIFY commands put you into the ACCENT R edit level to input and modify the items that consist of user-entered statements. These objects are Schema Definitions, System Files, Process Modules, Command Modules, Code Segments, Global Storage Definitions, Data Index Definitions, Index Definitions, and System Information's. Each of these elements is defined and modified by line-numbered statements entered at the edit level, which is invoked whenever a DEFINE or MODIFY command is used.
All items created with the DEFINE command are stored in the Data Base Library with the exception of System Files. System Files are stored in disk files outside the DBL, and their user-assigned names can be cataloged in the DBL. This chapter covers creating a DBL, creating Data Sets, defining and modifying Index Definition and Command Modules.
The text editor invoked in ACCENT R by the DEFINE and MODIFY commands is determined by the value in the system field @EDITOR. The default editor is Text Editor (TED) with a double hyphen prompt (--). TED can invoke Single Line Image editing (SLIM).
The user may choose to use a different editor by setting the @EDITOR system field to specified editor (see example below). Some of the other text editors that are available are the Digital Standard Editor (EDT), Extensible Versatile Editor (EVE), and EMACS. When exiting an alternate editor, control will be passed to TED for the text to be SAVEd. (Compile and display error messages if applicable, then exit) or HOLD to save modifications without compiling and STOP to exit with saving the text.
PURPOSE: The CREATE DBL command establishes and declares a Data Base Library, which is the primary organizational and control item of an ACCENT R application. See Chapter 3 for a full description of Data Base Libraries.
|
CREATE DBL name |
name is the user-assigned name of the Data Base Library established with this command. For the syntax of DBL names, see Chapter 2. The default extension is .DBL. |
|
When a DBL is created, it becomes the current DBL. The USE DBL command is not required. |
NOTES: A DBL must not be renamed or changed outside of the ACCENT R system, for it would then be unrecognizable by ACCENT R. Do not name the DBL the same name as a logical you have defined.
*CREATE DBL PROD
This creates a system file named PROD.DBL and writes a header block in it which it, which identifies it as an ACCENT R DBL.
PURPOSE: The CREATE DS command creates a Data Set (DS) and associates it with a Schema Definition (SD). The command can be used to create a new DS or to associate it with existing file file as a DS and and associate it it with the current Data Base Library (DBL) entry. If the KEYED ON clause is used, this command also defines a RAM Data Index (DI) for the DS. This command may be used to create a table or attach to a table within a data server such as Oracle, and RMS, and Sybase.
CREATE DS name SD /IS/ sd_name
[CREATE /IF MISSING/; ENTRY/ONLY/; ATTACH]
[KEYED ON field1 [… AND fieldn]]
|
name |
assigns the the name to the DS established with this command. Unless the ATTACH clause is specified a file or table will be created for the data set. |
|
sd_name |
references an an existing SD that describes the DS being established with this command. See DEFINE SD in this chapter for information on defining SD’s. The associated SD must exist before the CREATE DS create/if missing/ command is issued. |
|
creates a DBL entry for the DS, then checks for the existence of the associated DS file or table and creates it if it does not exist. If a DS file or table already exists, ACCENT R attaches it to the DBL entry, and it is recognized as the data for the DS. The SD referenced in the command must already exist in the current DBL, and its description must match the format of the records in the attached table if the table exists. See the notes that follow on attaching a DS. |
|
|
creates a DBL entry for the DS but does not check for the existence of an associated DS file or table. |
|
|
specifies that a table file or table exists outside the current DBL is to be recognized as the data for this DS. If no file or table of the specified DS name exists, ACCENT R aborts the command and displays an error message. |
|
|
[.KEYED ON field] [… AND fieldn]] |
names the fields that will serve as domains in a RAM DI established with this command. A DI created by this command has the same name as the DS with the extension .DI. Each domain will have only one field, and the domain name will be the same as the field name. The options DUPLICATES ALLOWED and KEY CHANGES ALLOWED are assumed. See DEFINE DI in this chapter for more discussion on the creation and use of DI’s. |
The following example assumes the system file SALES_DBM2.DS exists.
*CREATE DS SALES_DBM2 SD IS SALES_DBM2 ATTACH
This example will create the system file SALES STORES_DBM2.DS for the Data Set,; the system file for the DI called (STORES_DBM2.DI) and a DI entry in the DBL.
*CREATE DS STORES_DBM2 SD IS STORES_DBM2 KEYED ON ZIP AND STATE
NOTES: If a DBL entry for the specified DS already exists, ACCENT R aborts CREATE DS command and display an error message.
If an existing System File (SF) is referenced in the CREATE DS command without the CREATE IF MISSING, ENTRY ONLY or ATTACH option, ACCENT R aborts the command and displays an error message.
Attaching a DS simply creates an object in the DBL for the attached DS, ACCENT R does no error checking when a DS is attached. The system field @RECORDS for an attached DS is zero unless updated by the COUNT command. You can use the CHECK command instructing the ACCENT R to check the data against the SD definition.
PURPOSE: The CREATE SF command creates an empty system file.
CREATE SF name
|
name |
creates a system file by the name specified with the extension .CMD if no extension is given. |
Data Indexes (DI) represent an easy method of increasing the efficiency and convenience of accessing Data for DB-MACH2. They provide a means of accessing records in a DS by establishing a set of keys or record addresses to extract given records without sequential reading the records. They are used to get different logical sequential views of the DS, or to access subsets of records in the DS.
DI’s substantially increase efficiency and response time for almost all data manipulation. Only in the following is sequential access likely to be preferable to the use of a DI:
When every record is being accessed and the order is not important.
The indexing method offered by ACCENT R is called Rapid Access Method (RAM). RAM DI’s can be used on any ACCENT R DS. Special clauses, which can be included in most of the data manipulation commands, control indexed access to DS’s. In addition, special clauses for use in the GET statement in a Process Module allow RAM Data Indexes to be used for auxiliary DS’s.
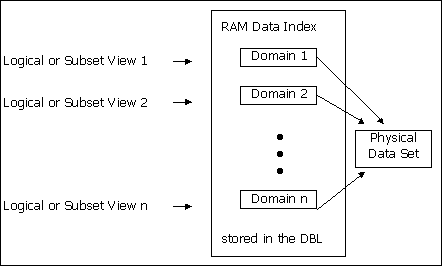
The creation, maintenance, and use of indexes have been simplified by allowing the combination of several logical sequences or subset views to be defined in a single DI. In ACCENT R terminology, each ordering or view is called a domain and multiple domains may be grouped into one DI. The combining of multiple domains into one DI means that all domains can be formed and updated with one command. You may define as many DI’s for one DS as required.
Figure 5-1 illustrates the power and flexibility of storing multiple views (domains) in one table (DI). Alterations, additions, and deletions are immediately reflected in all domains if the DI is declared during processing. In addition, the logical order of accessing the DS or the subset can be changed during processing by merely changing the domain used.
Figure 5-1 Multiple Domains in One Data Index
Each RAM Data Index DI) is a separate System File (SF), derived from the associated Data Set (DS). The Data Base Library (DBL) records the connection between the DI and the DS, and note that changes are made to the DS when the DI is not active.
Each RAM DI domain is a multi-level tree structure. Key values from each record are stored in the tree with information about the tree structure itself. The key values are those from the field(s) that are named as key in the definition of the domain. The tree structure permits:
Retrieval of specific records by matching all or a left subset of the key field values.
Retrieval of records in a logical order different from the physical order of the data.
Accessing a subset of the data.
A single data set may also have multiple indexes associated with it. If you normally access a data set in one or more sequences on a daily basis but at the end of the month need several other sequences required for reporting then two indexes can be set up. One index contains sequences used daily and one that contains the sequences used monthly. This can help decrease index maintenance when records are updated.
The paragraphs that follow summarize the ACCENT R commands and clauses that pertain to RAM Data Indexes. For more details about any of these features, see the individual discussion of the feature elsewhere in the manual.
To create a DI, the domains of the DI are defined with the DEFINE DI command, (A RAM Data Index can also be defined with a special clause of the CREATE DS command, if default options are acceptable.)
The DEFINE DI command creates an entry in the DBL and creates an empty System File (SF), but does not index the data. The indexing is done automatically the first time the DI is used, or it can be done as a separate step by issuing the FORM DI command.
The DI is activated (declared) by the DI clause of the USE DS command, or by a separate USE DI command after the DS has been declared. In Process Modules (PM), DI’s can be declared by RELATE statements.
After the DI has been declared, the domain that is to be used is specified by a USE DOMAIN clause in the command or in a GET statement in a PM. If no domain is named, the first is used by default. Since a USE DOMAIN clause is only in effect for the current command or statement, the next command or GET statement must specify which domain to use (or use the first is used by default).
ACCENT R provides several retrieval features that maximize the efficiency of RAM Data Indexes:
WHEN clause is a special conditional clause, used in the Simple Data Manipulation Commands, to specify search values for key fields. It is much more efficient than the IF; UNLESS clause. The IF; UNLESS clause can also be used, either with the WHEN clause, or by itself.
MATCH BY clause is used to specify match fields for transaction processing.
All domains of a declared DI are automatically updated as the DS is updated. If an index is not active when changes are made to a DS, the index is flagged as obsolete, and will be automatically reformed the next time it is used, or it can be reformed by the FORM command. Defining a DI as STATIC (see discussion of General Statements below) will prevent that automatic reformation. Such a DI cannot be used until it is expressly reformed with the FORM command.
PURPOSE: ACCENT R offers two ways to create an index, with DEFINE DI or CREATE DS.
The basic command, DEFINE DI, places control at the edit level, where all domains of the Data Index (DI) can be defined or refer to an Index Definition (ID) containing the domains for the DI. This command gives maximum flexibility to control options. It also allows multiple domains, each with multiple fields.
The KEYED ON clause (in the CREATE DS command) can be used to create a RAM DI at the same time as the Data Set (DS) if the default options are desired. This command allows more than one domain, but each domain can have only one field. See CREATE DS earlier in this Chapter.
The DEFINE DI command and the KEYED ON clause of the CREATE DS command creates the definition of the DI, include an entry for it in the Data Base Library (DBL), and establishes an empty System File (SF). The definition can then be displayed by the command LIST DI name.
The DI itself is not built until it is used for the first time, or until the FORM DI, command is given.
DEFINE DI name [IN DBL dbl_name]
[ATTACH; CREATE /IF MISSING/ ENTRY /ONLY/]
|
name |
is the user-assigned name of the DI. If an extension is not specified, the default extension DI is used. |
|
[IN DBL dbl_name] |
is used to define the DI entry in a DBL other than the current one. A DI must be stored in the same DBL as the DS that it indexes. If an IN DBL clause is included, the DI will be cataloged in the DBL named in that clause. Otherwise, it will be cataloged in the current DBL. |
|
is used to create the definition when the System File (SF) for the DI already exists. The text must be entered that defines the DI. Attaching does not cause the existing index to reform, but flags it as obsolete. The DI must then be formed by the FORM command before it can be used. |
|
|
defines the DBL entry of the specified DI, checks for the existence of the associated System File when the DI definition is saved, and creates the System File if it does not exist. |
|
|
creates the definition for the specified DI, but it does not check for the existence of the associated SF or attempt to create one when the entry is saved. |
*DEFINE DI BOOKS_DBM2
--INSERT
--00100 INDEX TYPE IS RAM
--00110 INDEX TO BOOKS_DBM2
--00120 !
--00130 DOMAIN TITLE_CODE ON TITLE_CODE
--00140 DUPLICATES NOT ALLOWED
--00150 !
--00160 DOMAIN TYPE ON TYPE_CODE
--00170 DOMAIN PUB ON PUB_CODE
--00180 END
--SAVE
PURPOSE: The statements in a Data Index (DI) are of two kinds: general statements, which apply to all domains in the DI, and specific statements, which define each domain. The general statements appear only once; they precede the definition of any domain, and must appear in the order shown below. The specific statements then follow, one set for each domain defined.
The DEFINE DI command transfers control to the ACCENT R editor, where these statements can be entered. ACCENT R defaults to the TED/SLIM editor. The user may specify a different editor by setting @EDITOR. ACCENT R will invoke TED to save and compile files after other editors (if used) are exited. The TED editor prompt is a double dash (--).
INDEX TYPE /IS/ RAM
INDEX ID /IS/ID_ name
INDEX TO ds_name
[INDEX /IS/ STATIC [OVERRIDE]]
[GROWTH FACTOR IS n% ]
(Specific Statements for Each Domain)
DOMAIN name ON \\[-]fields\\
[DUPLICATES [NOT] ALLOWED]
[KEY CHANGE [NOT] ALLOWED]
[ENTER {IF; UNLESS} clause]
Within each domain definition, these statements (except the first) can be in any order. There is no limit to the number of domains that can occur in one DI.
|
INDEX TYPE/IS/RAM |
specifies that a RAM DI is to be built. This statement is required. |
|
INDEX ID /IS/ID_name |
this specifies an Index Definition. See Index Definition for details. If this statement is present then only the "INDEX TO" statements is allowed. |
|
INDEX TO ds_name |
specifies the name of the DS associated with this endex. |
|
[INDEX/IS/ STATIC] |
is an optional statement that prevents automatic reformation of the index. By default, if a DS is changed, any index not active at the time is flagged as obsolete. When that index is later activated and used, it is, automatically, FORMed. It also prevents the index from being used in its present form. It must be explicitly updated with a FORM command before it can be used. |
|
[OVERRIDE] |
the STATIC option directs ACCENT R not to automatically reform it. OVERRIDE allows use of an obsolete index. This feature should be used with caution because it overrides ACCENT R's validity check of the index. There are times when the developer knows it is not obsolete and can be used in it’s present form. This is when override should be used. |
|
[GROWTH FACTOR IS n%] |
specifies the expected percentage growth of the associated DS. The growth factor specified in this statement can be overridden by the FORM command. If this statement is not specified, the default percentage growth factor is 200%. This factor controls the efficiency of the initial additions immediately after the index is formed. As new records are added the index is automatically restructured to facilitate more additions. The index is self-balancing, and FACTOR IS n% should only be specified if the associated DS is expected to more than 300%. |
|
[DOMAIN name ON \\ [-]fields\\ |
names the domain and specifies the field or fields that make up the key to the domain. The domain name can be a field name, and each domain can have any number of key fields. This statement is required for each domain, and must be the first statement for that domain. If the domain is to be in descending order, the field name is prefixed with a minus sign (-). Multiple domains permit records to be retrieved in multiple sequences. The access order of the Data Set may be changed by merely changing the domain. |
|
[DUPLICATES [NOT] ALLOWED] |
controls whether more than one record in the Data Set is allowed to have the same key value. The default is DUPLICATES ALLOWED. The NOT option is more efficient for adding records because it does not have to check for the key value before storing it. If adding a new record or changing an existing record causes a duplicate violation for any domain, the record will not be added or changed and a warning message will be displayed. |
|
[KEY CHANGE [NOT] ALLOWED] |
controls whether changes to key field value(s) are allowed. The default is KEY CHANGE ALLOWED. If the changing of a record causes a key change violation for any domain, the record will not be changed and a warning message will be displayed. If key changes are allowed, the processing of each change to a key field value involves considerable internal checking, and is therefore costly. |
|
[ENTRIES PER NODE IS n] |
gives control over the major efficiency retrieval factor, the number of key entries per node. The number of entries per node can have a substantial impact on retrieval time depending on the number of levels in the index tree. Programmers are therefore encouraged to use the programs supplied in DBL ACCUTL, called RAM and LEVELS to optimize retrieval efficiency. If this statement is not specified, the default number of entries per node is eight. This default value is designed to minimize memory usage; it is not designed for the most efficient retrieval. |
|
[ENTER {IF;UNLESS} clause] |
expresses a condition that a record must pass to be referenced in the domain. The clause can contain any of the conditionals described in Chapter 6. It can test DS fields, system fields, and constants. Global Storage (GS) fields are not allowed. When the DI is formed, the clause is examined for every record in the DS. This statement is optional for each domain. If it is not included, all records in the DS will be indexed in the domain. |
*LIST SD STORES_DBM2
00100 STORE_CODE,CHAR,4
00110 STORE_NAME,CHAR,30
00120 STORE_ADDRESS,CHAR,30
00130 CITY,CHAR,20
00140 STATE,CHAR,2
00150 ZIP,CHAR,5
00130 COUNTRY,CHAR,20
*LIST DI STORES
00100 INDEX TYPE IS RAM
00110 INDEX TO STORES_DBM2
00120 !
00130 DOMAIN CITY ON CITY
00140 !
00150 DOMAIN STATE ON STATE
00160 DOMAIN WASH ON STATE ENTER IF STATE = ‘WA’
00170 DOMAIN CALIF ON STATE ENTER IF STATE = ‘CA’
00180 DOMAIN OTHER ON STATE ENTER IF STATE # ‘WA’ AND # ‘CA’
00190 !
00200 DOMAIN COUNTRY ON COUNTRY
*LIST DI PUBLISHERS
0100 INDEX TYPE IS RAM
0110 INDEX TO DS PUBLISHERS
1120 DOMAIN PUB_CODE ON PUB_CODE
*LIST DI PUBLISHERS
0100 INDEX ID IS PUBLISHERS
0110 INDEX TO DS PUBLISHERS
PURPOSE: The DEFINE ID command creates an entry for an Index Definition (ID) in the Data Base Library (DBL) and transfers control to the edit level, where the index definition statements can be entered.
An Index Definition (ID) defines a general index definition for a Schema Definition (SD), which can then be used to create Data Indexes (DI) for any Data Set (DS) that is associated to the SD.
DEFINE ID name [IN DBL dbl_name]
|
name |
is the name assigned to the ID being created. |
|
[IN DBL dbl_name] |
is used to define the ID in a DBL other than the current one. If an IN DBL clause is included, the ID will be cataloged in the DBL named in that clause. Otherwise, it will be cataloged in the current DBL. |
*DEFINE ID PUBLISHERS_DBM2
--00100 INDEX TYPE IS RAM
--00110 INDEX TO SD PUBLISHER_DBM2
--00120 !
--00130 DOMAIN PUB ON PUB_CODE
--00140 DUPLICATES NOT ALLOWED
--00150 !
--00160 DOMAIN CITY ON CITY
--00170 DOMAIN STATE ON STATE
--00180 END
-—SAVE
PURPOSE: An Index Definition (ID) defines a general index definition for a Schema Definition (SD), which can then be used to create Data Indexes (DI) for any Data Set (DS) associated with this SD.
ID’s eliminate the need to have duplicate sets of index definitions for the different DS’s associated with an SD. The individual DI’s for these DS’s simply reference the ID, much like multiple DS’s referencing the same SD. One of the advantages of an ID is that it can be related in a generalized Process Module (PM). The PM can be used with different DI’s at run time.
Figure 5-2 illustrates the relationships between a SD, an ID, and their associated DS’s and DI’s.
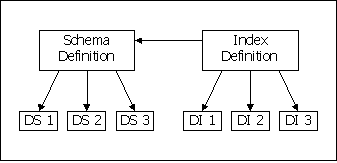
Figure 5-2 Relationships between Schema Definition and Index Definition.
The statements used in an ID are identical to those used in the DI definitions, with the exception that the second statement references a SD rather than a DS name.
INDEX TYPE IS RAM
INDEX TO SD sd_name
[INDEX/IS/STATIC [OVERIDE]]
[GROWTH FACTOR IS n%]
See the definition given for DI earlier in this chapter. In an ID definition, the INDEX TO statement must specify the name of an SD rather than a DS as in a DI definition.
The following example shows a Schema Definition (SD) with two Data Sets (DS) and two Data Indexes (DI). The two DS’s share a common SD and the two DI’s share a common ID.
*LIST SD PUBLISHERS_DBM2
00100 PUB_CODE,CHAR,4
00110 PUB_NAME,CHAR,40
00120 CITY,CHAR,20
00130 STATE,CHAR,2
00140 COUNTRY,CHAR,20
*LIST ID PUBLISHERS_DBM2
00100 INDEX TYPE IS RAM
00110 INDEX TO SD PUBLISHERS_DBM2
00120 DOMAIN PUB_CODE ON PUB_CODE
00130 DOMAIN PUB_NAME ON PUB_NAME
*LIST DI ONE_DI
00100 INDEX ID IS PUBLISHERS_DBM2
00110 INDEX TO DS PUB_ONE
*USE DS PUB_ONE DI PUB_ONE
*EXTRACT SHOWING PUB_CODE,1b,PUB_NAME
1030 Royal Empire
1227 East Meets West
1944 Comp & Ling
*LIST DI PUB_TWO
00100 INDEX ID IS DPUBLISHERS_DBM2
00110 INDEX TO DS PUB_TWO
*USE DS PUB_TWO DI PUB_TWO
*EXTRACT SHOW PUB_CODE,1B,PUB_NAME
2145 Blue Sky Pub
7789 Best Books
2346 Reading Plus
Index Definitions (ID) can be related in a Process Module (PM). Relating an ID in a PM is analogous to relating a Schema Definition (SD). Relating a SD allows different Data Sets (DS) of the specified SD to be used in the PM. Likewise, relating an ID allows different Data Indexes (DI) of the specified ID to be used in the PM.
When invoking the PM, an EQUATE clause assigns the specific DI for use in the current session of the PM.
*LIST PM DEMO
00100 CONTROL SECTION
00110 RELATE ID PUBLISHERS_DBM2 AS PUB FOR UPDATE
00120 DETAILS SECTION
00130 START
00140 GET FROM PUB NEXT RECORD HUSH
00150 LEAVE IF @AUX NE "YES"
00160 TYPE PUB_CODE,2B,CITY_PUB_NAME
00170 REPEAT
*USE PM DEMO
?Designator AUX was not assigned to a DI in the command
*USE PM DEMO EQUATE PUB_ONE TO PUB
1030 Royal Empire
1227 East Meets West
1944 Comp & Ling
*USE PM DEMO EQUATE PUB_TWO TO PUB
2145 Blue Sky Pub
7789 Best Books
2346 Reading Plus
NOTES: The contents of ID’s are stored in the DBL file in which they were defined.
An ID cannot be removed when it has one or more DI’s associated with it.
PURPOSE: The DEFINE SI command creates an entry in a Data Base Library (DBL) for the System Information (SI).
A SI provides an object within the DBL for the storage of non-executable text. Its major purpose is to provide the user with a means of documenting applications which define the scope of all objects used in the implementation of the application. Overview and operational aspects of an application should be documented in a SI. A well-documented application makes the job of on going maintenance easier.
DEFINE SI name [IN DBL dbl_name]
|
name |
is the name assigned to the SI object. |
|
[IN DBL dbl_name] |
is used to define the SI in a DBL other than the current one. If an IN DBL clause is included, the SI will be entered in the DBL named in that clause. Otherwise, it will be entered in the current DBL. |
PURPOSE: A System File (SF) may be created externally or within ACCENT R by using the DEFINE SF command, which invokes the edit level where the lines that make up the SF are entered.
A SF can contain any line that could be entered at the terminal, including data, commands, editing commands or comments.
Once they are defined and saved, SF’s can later be modified with the MODIFY SF command, which also invokes the edit level.
DEFINE SF name [ENTER /IN DBL/]
|
name |
assigns a name to the SF established with this command. The default file name extension is CMD. |
|
[ENTER /IN DBL/] |
specifies that the name of the SF to be stored in the Date Base Library (DBL) for documentation purposes. |
*DEFINE SF TRAIL
--10 ENABLE CPU TRACE
--20 ENABLE CM TRACE
--30 DISABLE ERROR ABORT
--40 SET 1000 TO @TERM_LINE
--50 DISABLE SF INPUT
--60 TYPE ‘ENTER CURRENT REPORT DATE:; NOCR
--70 ACCEPT @VDATE(1)
--80 ENABLE SF INPUT
--90 USE DS BANK
--100 REPORT VIA MONEY
--SAVE
NOTES: If an SF by the specified name already exists, ACCENT R displays an error message and aborts the command.
The CREATE SF command, described earlier in this chapter, establishes or attaches an SF, but does not call up the edit level for text entry. From the ACCENT R frame of reference, every file that resides on disk is a SF.
ACCENT R provides the ability to accept command from a text file. It will also accept data intermingled with the command text.
ACCENT R identifies these files simply as System Files (SF). SF’s can contain any ACCENT R command. If the command STORE is used in a SF, it must include the option NEXT. Several commonly used commands could be stored in a SF with the STORE NEXT AS name command. After declaring the SF, any of the commands could be invoked with the INVOKE name command.
The TYPE SET and ACCEPT commands are permitted with conditional clauses. System fields, declared Global Storage (GS) fields, literals, constants, functions, and expressions can be included in the TYPE ACCEPT or SET commands.
A SF cannot contain the control statements IF; UNLESS, START, LEAVE, or REPEAT.
Data Set (DS) fields, GS fields, and system fields can be referenced where the syntax of the command permits.
SF’s are not compiled when they are saved. The only way to check a command file for logical or semantic errors is to execute it. A given SF can contain data as well as commands.
SF’s can call other SF’s, that which can in turn call other SF’s up to ten levels. When a SF calls another SF control immediately passes to the next level SF. When the next level SF runs to completion, it then returns control to the line following that, which called it in the first SF. However, a USE NO SF command in any SF breaks out of all SF’s and returns control immediately to the interactive command level or the calling CM.
Within a SF, the USE DBL command causes the current DBL to close, and all further lines in the System File must operate only in the DBL declared by the USE command. A later USE DBL command could return processing to the first DBL, or could pass to a third DBL.
The command TERMINAL can be included in an SF to allow a command to be entered interactively during SF execution. There is no limit to the number of TERMINAL commands that can be included in an SF and they can follow one another. The SF cannot control the execution of the line entered. If terminal input is erroneous, ACCENT R does not permit reentry, but continues processing with the next SF line.
When a System File is executed, any lines that ACCENT R would normally display on the terminal are displayed, but the lines of the System File are not themselves displayed unless ENABLE SF TRACE is in effect.
The following example shows a System File (SF) that declares a Data Set (DS), then counts the records in it. The SF is invoked with TRACE disabled (the default), then with TRACE enabled.
*LIST SF CHCK
00100 USE DS SALES_DBM2
00110 COUNT
*USE SF CHCK
21 RECORDS
*ENABLE SF TRACE
*USE SF CHCK
<<SF 00100 USE DS SALES_DBM2
<<SF 00110 COUNT
21 RECORDS
NOTES: When an SF is executing, ACCENT R displays any error or warning message that would have occurred if the command had been entered interactively. The SF aborts if an error occurs in a command. Control is returned to the terminal. The command DISABLE ERROR ABORT can be used to force continued execution regardless of command errors.
SEE ALSO: STORE, INVOKE, TERMINAL, ENABLE/DISABLE SF INPUT
Command Modules (CM) take precedence over System Files (SF) by default. When a CM invokes an SF, the SF is accessible but control remains in the CM. When a CM is invoked from a SF, control immediately passes to the CM. If the CM contains no ACCEPT statements, it runs to completion, then returns control to the line following that which that, which invoked it in the SF. The command ENABLE SF COMMAND INPUT in a CM passes control to any open SF. Commands are then taken from the SF until the command DISABLE SF COMMAND INPUT is encountered.
Both CM’s and Process Modules (PM) can take DATA input from an SF. If a CM or PM contains an ACCEPT statement, by default, it accesses the SF for input. Only when there are no more lines in the SF does the CM or PM access the terminal for input. The statements ENABLE SF DATA INPUT (the default) and DISABLE SF DATA INPUT are allowed in both PM’s and CM’s. These two statements control whether data for an ACCEPT statement comes from a SF or the terminal. In the default state, if any SF is declared, input will be taken from the SF. DISABLE SF DATA INPUT is used to override the default state and accepts data from the terminal. DISABLE does not close the SF, and, if an ENABLE statement subsequently occurs, the PM or CM will return to the SF and accept data from the next line of the SF. To ENABLE or DISABLE both DATA and COMMANDS use ENABLE/DISABLE DISABLE SF INPUT.
DISABLE SF DATA INPUT can not be used in an SF to force data to be accepted from the terminal, instead you must use the TERMINAL command
ACCENT R provides for automatic startup at three levels, by looking for the file BEGIN.ACC in each level. ACCENT R also provides for an automatic shutdown procedure to be executed when ACCENT R is exited thru the use of QUIT.ACC files. Thru the use of the BEGIN.ACC, the system manager can gather information about ACCENT R users. Application designers can control what the application users have access to and direct them to specific functions. Individual users can use their own BEGIN.ACC to set up their working environment by defining terminal characteristics, equated commands and their working DBL.
ACCENT R supports the execution of up to three start-up command files. It is possible for all three command files to be executed.
NIS:BEGIN.ACC (system-wide) can be used to set Equated Commands, set a system-wide default editor, override the GUIDE full screen menu mode, etc. This will permit the System Manager to control access to ACCENT R and monitor usage.
BEGIN.ACC (log-in directory) will permit the user to have a central startup command file without copying it to every working directory.
BEGIN.ACC (connected directory) allows the use of a locally specific startup file to set specific environment standards desired by the end user only.
ACCENT R supports the execution of up to three terminating or exiting command files. It is possible for all three command files to be executed.
QUIT.ACC (connected directory) allows the use of a locally specific exit command file.
QUIT.ACC (log-in directory) will permit the user to have a central exiting command file without copying it to every working directory.
NIS:QUIT.ACC (system-wide) will permit the System Administrator to control the exit of ACCENT R.
A startup file that would take the user directly from entering ACCENT R at the terminal to the first question in the Command Module (CM) follows:
*LIST SF BEGIN.ACC
0001 USE DBL BIZNIS
0002 TYPE "GOOD MORNING!"
0003 TYPE "IT’S ",@CTIME," ON ",@CDATE
0004 TYPE "LET’S GET STARTED."
0005 USE CM PRICE
The beginning of an ACCENT R session with this BEGIN.ACC file in effect is shown below.
@ACCENT
GOOD MORNING!
IT’S 08:08 ON 11/11/85
LET’S GET STARTED
The screen would then clear and the PRICE program’s screen/menu would appear.
NOTES: Command files are not needed to start or end an ACCENT R session. Of the command files listed, any one, two or all three of each type (BEGIN/QUIT.ACC) may be used. The order of execution in using multiple command files is set at each site by the System Manager. Refer to the ACCENT R OpenVMS Installation Guide for specifying the execution order.
ACCENT R provides a second type of startup file for use when transferring control to ACCENT R from a running program. When a program transfers control to ACCENT R by executing a LINK statement, it can take commands either from a BEGIN.ACC file, or from a file named ###ACC.TMP. The procedure for using a TMP file assumes that the TMP file is itself written by the program each time it executes, and so will be used only once.
The default order of execution of BEGIN.ACC is:
NIS: (system level)
Login directory
Local directory
The default order of execution of the QUIT.ACC files is the reverse of the BEGIN.ACC files.
SEE ALSO: Execution Order of BEGIN.ACC, QUIT.ACC - (ACCENT R OpenVMS Installation Guide).
ACCENT R can be invoked from a Digital Command Language (DCL) command file without any special considerations under normal conditions. However, when the BEGIN.ACC for start-up executes a Process Module (PM) or Command Module (CM), which makes use of ACCENT R’s window development language, SMF (Screen Management Facility), or requires input from the file or input to come from terminal and not from a command, the application will not start correctly. With SMF applications, the SMF-based FILL or MENU screen will send bells to the terminal and flash the cursor. This is due to a limitation in the OpenVMS SMG Library. For CM’s or PM’s that require terminal input, the error message "%RMS-E-EOF, end of file detected" is displayed at the first place where user input is expected.
In order to start the application correctly, the DCL command procedure must first reassign the process logical for command input with the following DCL command:
$ ASSIGN/USER/NOLOG SYS$COMMAND SYS$INPUT
This logical name is temporary and will be designed automatically by DCL.
The contents of the command procedure might be the following:
$ !
$ ! USER.COM
$ !
$ ASSIGN/USER/NOLOG SYS$COMMAND SYS$INPUT
$ ACCENT
The contents of BEGIN.ACC in the user’s directory:
! User's BEGIN.ACC file
!
TYPE @VERSION@''
SET 'EDIT/EDT' TO @EDITOR
USE DBL USER_LIB
USE DS NISDATA:BOOKS
USE PM BOOKS_MAIN_MENU
QUIT
Command Modules (CM’s) contain ACCENT R commands and statements that provide for repetitive or conditional execution. A complete application usually consists of many different Process Modules and commands for tasks such as data entry, updating, deleting or moving records, and reporting. Command Modules are used to tie the individual subsystems together into a complete application system. Menu-driven systems are easily implemented with the use of Command Modules.
Command Modules are best used to execute actions that apply to either all records of a given data set or an easily identifiable subset where the action for each record is the same. Command Modules are used to perform sorting, merging, deleting, and renaming and such other conditioning executions. They are used to set up the environment prior to executing a PM. For example:
USE DS INVOICES
SORT ON INVOICE_NO
REPORT VIA MAKE_INV_STATEMENTS
Commands Modules are also often used to store a single command. Particularly a frequently used commands that is several lines long.
Command Modules are not as efficient as Process Modules, since PM’s are fully compiled while many lines in CM’s must be partially interpreted as they are executed. Applications should therefore be designed so that as many tasks as possible are done in Process Modules.
Command Modules can contain almost any command that can be entered at the terminal. They can also contain control statements, which provide for iterative or conditional execution. Command Modules may call other Command Modules, so that applications can be designed modularly.
Only one command or statement can appear on a line. A command may open several lines thru the use of the line continuation character “&”. A comment can follow a command or statement on a given line; the comment must begin with an exclamation point (!). Maximum line length is 4095 characters, by default. Line length can be changed with @TERM_LINE.
Any command in a CM can be prefaced with an asterisk (*) to create a debug statement. Debug statements compile and execute only when the DEBUG option is specified in the SAVE editing command.
CM’s may execute other CM’s to a nested depth of 10. Although they can be executed recursively, there is no provision for saving the current environment automatically. Global storage could be used to stack information on successive calls.
PURPOSE: A Command Module (CM) is created with the DEFINE CM command, control is transferred to the edit level, where the text of the CM is entered. Once CM’s are defined and saved, they may later be modified with the MODIFY CM command, which also transfers control to the edit level. A CM is executed with the command “USE CM name”.
CM’s are user-defined programs that consist of commands and control statements. They are generally used to control all or a significant portion of an application.
DEFINE CM name [IN DBL dbl_name]
|
name |
is the user-assigned name of the CM being created. |
|
[IN DBL dbl_name] |
is used to define the CM in a DBL other than the currently in use DBL. |
*LIST CM SALESCHECK
00100 USE DS BOOKS
00110 TYPE "DO YOU WANT TO ADD DATA?--Y OR N? ",NOCR
00120 ACCEPT @STRING
00130 IF @STRING = "Y"
00140 ENTER WITH PROMPTS
00150 SORT ON TITLE_CODE, TYPE_CODE
00160 CONTINUE
00170 TYPE "DO YOU WANT A REPORT?--Y OR N? ",NOCR
00180 ACCEPT @STRING
00190 IF @STRING = "Y"
00200 REPORT VIA BOOKREP
00210 CONTINUE
When the SAVE command is given, ACCENT R performs a symatic and syntax check on the entire CM. If errors are found, ACCENT R displays an appropriate error message and leaves control at the edit level so that the CM can be corrected. If the symatic and syntax are found to be correct, SAVE compiles the CM, saves it in executable form, and returns control to the command level.
The HOLD editing command saves the text of the CM but does no checking. The CM cannot be executed until it is saved with the SAVE command. HOLD also leaves control at the edit level, which can be exited by typing STOP.
SEE ALSO: ENABLE CM TRACE
ACCENT R allows any interactive command that can be entered at the terminal to be used, except DEFINE, MODIFY, STORE, INVOKE, and RECALL. A command within a CM executes exactly the same as when entered at the terminal. Commands can be abbreviated in CM’s.
There are two CM statements valid only in a CM. These are DONE and EXIT CM.
Both DONE and EXIT CM will terminate the current CM and return control to the command level of ACCENT R. If the current CM was executed from a CM or a SF then control returns to the next statement in the CM or SF.
The command USE NO CM can be included in a Command Module to stop execution and exit all nested CM’s. QUIT can be used to directly exit ACCENT R from a CM or nested CM’s.
Dynamic Command Modification, which constructs commands by incorporating string variables, is a particularly useful feature when used in Command Modules.
Conditional block control statements allow for conditional execution of commands and statements in a command module. The conditional statements are:
{IF; UNLESS} [:n] conditions
[Commands or statements]
[{ORIF; ORUNLESS} [:n] conditions]
[Commands or statements]
[{ORIF; ORUNLESS} [:n] conditions] [Commands or statements]
.
.
.
[ELSE[:n]]
CONTINUE[:n]
These statements function exactly as they do in PM’s, except that they cannot reference Data Set fields.
Groups of statements and commands within a Command Module can be executed repeatedly through with the use of a START/REPEAT loop. These loops are like the START/REPEAT loops in Process Modules. , With two exceptions: Command Module loops cannot reference Data Set fields, and the START statement cannot include a for clause, and therefore must always have at least one corresponding LEAVE statement.
The form of the Command Module loop statements is:
START[:n]
[Commands or statements]
LEAVE[:n] [IF;UNLESS clause]
[Commands or statements]
LEAVE[:n] [IF;UNLESS clause]
[Command(s) or statement(s)]
.
.
.
REPEAT[:n]
SEE ALSO: Conditional Clauses & Expressions, Interactive Commands, Enable/Disable SF Command Input, Use CM Command and @CM.DBL
PURPOSE: The EXIT CM statement terminates execution of the current Command Module and returns control to the calling Command Module if there is one. This statement can be combined with conditional block control statements to provide for conditional termination of a CM.
EXIT CM
NOTES: If the Command Module that contains the EXIT CM statement was called from another Command Module, control is passed to the calling CM. To exit all nested CM’s and return control to the terminal, use the command USE NO CM.
The EXIT CM statement is not needed for normal CM termination. When the last statement in a CM has finished executing, the CM is closed and control is returned whence it came.
SEE ALSO: USE NO CM, USE CM
PURPOSE: The DONE statement terminates the execution of the current Command Module and returns control to the calling Command Module if there is any. This statement can be combined with conditional block control statements to provide for conditional termination of a CM.
DONE
NOTES: If the Command Module that contains the DONE statement was called from another Command Module, control is passed to the calling CM. To exit all nested CM’s and return control to the terminal, use the command USE NO CM.
The DONE statement functions the same as the EXIT CM statement.
The DONE statement is not needed for normal CM termination. When the last statement in a CM has finished executing, the CM is closed and control is returned whence it came.
There are two ways to designate DBL’s in a Command Module (CM): by using the USE DBL command as a line in the CM or by using an IN DBL clause in an object declaration. The System Field @CM_DBL contains the name of the Data Base Library (DBL) from where the current CM is running or by specifying and “IN DBL” clause. This field does not change when the default DBL is changed. This field will contain the name of the last CM executed if no CM is being executed.
USE DBL STOCK
USE DS ASB IN DBL STOCK
USE DS ABC IN DBL @CM_DBL
The TYPE and ACCEPT commands allow for terminal input and output. They function in CM’s exactly as they do in PM’s.
The command TERMINAL can also be included in a Command Module to allow interactive entry of a command.
Input can be taken from a System File rather than the terminal by using the ENABLE SF DATA INPUT command.
PURPOSE: Global Storage (GS) is a set of user-defined fields that define an area in memory where information can be stored and passed on from CM and PM to other CM’s, PM’s and even direct commands. It is also possible to share data with programs running simultaneously even those being executed by other users. GS fields are similar in function and syntax to the fields in Schema Definitions (SD) except:
Current GS Values exist only until the ACCENT R session is terminated with the QUIT command, or until another USE GS, command is executed.
GS field names are always preceded by a percent sign (%).
Items in the GS can have initial values specified when the item is defined.
Each GS defines an area in memory whose default FORM is binary.
GS areas are very useful for storing values that are to be used from command to command and exceed the capacity provided by the system fields @STRING, @NUMBER, @INTEGER, @VDATE, AND @COMMAND
Any number of GS areas may be defined, but only 10 may be in use at a time. The values stored in Global Storage are lost when the USE GS for that GS is executed again or USE NO GS command is issued or the current ACCENT R session is terminated. The field definitions for GS, however, endure until specifically removed or modified.
Once a GS area has been declared with USE GS command, the fields in that GS can be accessed for either input or update from any DBL in the user’s directory. Closing a Data Base Library (DBL) does not close the GS area.
Up to ten GS’s can be declared and accessed. If more than one declared GS has a field by the same name, the first declared GS’s definition would apply. Individual GS’s can be closed with the command USE NO GS GS.name.
A GS definition is created with the DEFINE command. The DEFINE command transfers control to the edit level, where the field definition statements and any of the following options may be entered.
DEFINE GS name [IN DBL dbl_name]
|
name |
is the name assigned to the GS being created. |
|
[IN DBL dbl_name] |
is used to create the GS entry in a DBL other than the current one. If an IN DBL clause is included, the GS will be stored in the DBL named in that clause. Otherwise, it will be stored in the current DBL. |
*DEFINE GS AUTHOR
--10 %NAME,CHAR,25
--20 %ADDRESS,CHAR,35
--30 %CONTRACT,INT,1,VALID IF VALUE = 0,1,2
--SAVE
NOTES: The names of GS definitions should not begin with ACC because this prefix is used by the ACCENT R utilities that use GS’s.
The field definition statement has the same clauses as are used in the field definition statement of Schema Definition (SD). See Chapter 4 for a detailed description of each clause. The DATA clause is only used for global storage definitions and is described in detail here.
[$start_position] %field_name, data_type,
[,{field_width; MAX} [, decimal_places]] [DATA value]
[,OCCURS m [[{BY; *} [n {BY; *} o]] [{RECORD; COLUMN} /MAJOR/]]
[,IE = "input_edit_string"]
[,OE = "output edit string"]
[,PP = "print_picture_string"]
[,TITLE = "title_string"]
[,\\ALIAS names\\]
[,OVERPUNCH]
[,/USAGE IS/ {ASCII; BINARY}]
[,USE VALUES \\field_value = "string"\\]
[,VALID conditional clause]
|
allows an initial value to be specified for the field. |
|
|
The DATA clause eliminates the need to set values to GS fields each time they are declared for use. |
|
|
value |
is the initial value of the right data type. For alpha and character fields, the value must be enclosed in quotation marks; for date fields, the value must be entered as an integer in the form YYMMDD (see example below). |
*LIST GS CUSTOMER
00010 %NAME,CHAR25
00020 %ADDRESS,CHAR,35
00030 %REGION,INT,1,VALID IF VALUE = 3,4,5,6
*USE GS CUSTOMER
*SET “RHONDA GARRETT” TO %NAME
*SET “123 OAK ST., FERNVILLE, CA” TO %ADDRESS
*SET 3 TO %REGION
*TYPE %NAME, %ADDRESS, %REGION,
RHONDA GARRETT 123 OAK ST., FERNVILLE, CA 3
The next example shows a Global Storage (GS) definition containing a DATA clause for each of its fields. Note the DATA clauses eliminate the need to set initial values to the fields.
*LIST GS DEMO
00100 %TEXT,CHAR,3, DATA “abc”
00110 %INT,INT,2, DATA 10
00120 %NUMBR,FLOAT,6,2, DATA 100.50
00130 %DUE_DATE,DATE, DATA 851230
*USE GS DEMO
*TYPE %TEXT,2B,%INT,2B,%NUMBR,2B,%DUE_DATE
abc 10 100.50 12/30/85
For items with OCCURS clause, the data is specified with “DATA” on a line following the item definition and each data line follows beginning with “ / ”. Data values must be separate by comma with the last data item followed on the next line with “DATA END”.
NOTES: The field names in a GS definition should not begin with %ACC because this prefix is used by ACCENT R utilities that use GS’s.
The following examples should help:
LIST GS RATES
00001 %RATE,1,2 OCCURS 3
00002 DATA
00003 /1.4,17,92
00004 DATA END
00005 %CODES,C,2, OCCURS 2 BY 3
00006 DATA
00007 /‘en’,‘at’,‘bt’,‘xa’, ‘yb’,‘hj’
00008 DATA END
00009 %DISC,I,2,OCCURS 3 BY 3
00010 DATA
00011 /5,9,11
00012 /12,14,17
00013 /25,50,75
00014 DATA END
Values for groups can be specified as follows:
LIST GS GROUP.EXP
GROUP EXP OCCURS 3 TIMES
%CODE,1,2
%TEXT,C,3
END GROUP
DATA
/10,’aaa’/
/20,’bbb’/
/30,’ccc’/
DATA END
PURPOSE: Instant Data Access is for applications where:
Users need immediate access to data.
Data changes frequently.
Data is accessed by many users at the same time.
Normally, data is accessed from files. The Instant Data Access feature uses shared physical memory (called a “global section”) that giving users immediate shared access to data.
An example is in a stock market application where data changes frequently and many users need to read the data. Instant Data Access allows the changes to be made in memory with all users knowing immediately when the data has changed.
You can use Instant Data Access to share data at the command level, among Command Modules, and among Process Modules.
First, you define you data in a Global Storage Schema Definition. See Global Storage Schema Definition earlier in this chapter.
When you start a process that needs the Instant Data Access feature, you give a command to declare the Global Storage with the “as global” clause. This specifies that the Global Storage is to be used as a Global Section. You can declare up to ten Global Storages with the “as global” clause. All other users that subsequently declare the same Global Storage with “as global” clause share the same data and can read the values written by the other user.
If you do not specify the “as global” clause when you declare a Global Storage, then the values written by others will not be available to you and your values will not be available to others.
Be extremely cautious when using two or more Global Storages with the same name as Global Sections. ACCENT R does not check to see if Global Storages with the same names have the same field descriptions. If one user declares the Global Storage called RATES from a different DBL as a Global Section, but the two Global Storages have different field descriptions, results are unpredictable. For example, the first user may write an Integer value to a field in RATES, and the second user may retrieve the value thinking that it is a character field. It is important that all Global Storage names be unique.
In this example, assume the Global Storage called STOCK has a field called %QUAN that has a DATA clause that specifies a value of 100. Also, assume that three users declare the Global Storage STOCK at the same time. The first two users declare STOCK with the “as global” clause (Instant Data Access) and the third user declares STOCK without the “as global” clause.
|
User 1 |
User 2 |
User 3 |
|
*USE GS STOCK AS GLOBAL |
*USE GS STOCK AS GLOBAL |
*USE GS STOCK |
|
*TYPE %QUAN |
*TYPE %QUAN |
. |
|
. |
||
|
*100 |
*100 |
. |
|
|
. |
|
|
*SET 200 TO %QUAN |
. |
. |
|
|
. |
. |
|
. |
. |
. |
|
. |
*TYPE %QUAN |
*TYPE %QUAN |
|
. |
|
|
|
. |
*200 |
*100 |
|
. |
*SET 400 TO %QUAN |
|
|
. |
*SET 300 TO %QUAN |
*TYPE %QUAN |
|
. |
*400 |
|
|
. |
. |
|
|
. |
. |
|
|
*TYPE %QUAN |
. |
|
|
. |
||
|
*300 |
. |
|
|
|
. |
|
|
|
SEE ALSO: Global Memory Section
Global Sections can be created for system-wide access or be limited to group access. They can be created as temporary or permanent sections. Global Sections are useful for sharing needed data between processes. Creating Global Sections in ACCENT R is much easier than doing it with a 3rd Generation Language (3GL).
Privileges are needed to use system-wide global sections. These Global Section privileges can be obtained through the SET command in the OpenVMS Digital Command Language (DCL):
$ SET PROC/PRIV=(options)
The options include: ALL (all privileges available)
PRMGBL (create a PERM/anent/ global section, either group or system)
SYSGBL (create a system-wide global section)
[* for effective QuickStart use]
$ SET PROC/PRIV=(PRMGBL,SYSGBL)
NOTES: The parentheses are only needed if multiple options are specified.
A temporary group global only requires normal defaults (SET command is not needed).
User must be authorized to use certain options.
To cancel privileges, log out and then back in again, or use the same syntax with the prefix of “NO” as part of each option.
$ SET PROC/PRIV=(NOSYSGBL,NOPRMGBL)
To see privileges currently set: $ SHOW PROC/PRIV
Global Sections are created within ACCENT R with the USE GS statement. The original USE GS syntax was kept intact for compatibility with existing Command Modules and System Files. The complete syntax is:
USE GS \\ gs_name [AS [PERM/ANENT/] [{GROUP}]
GLOBAL /SECTION/] \\ [{SYSTEM}]
NOTES: If GROUP or SYSTEM is not specified in the “AS GLOBAL” clause, ACCENT R reverts to its original design (retained for compatibility with existing user-level code). In the default mode, it is possible that two users might NOT share the same GS depending on which privileges were enabled for each. One user may get a group-wide global and the other may get a system-wide global.
An error in creating a Global Section will set @ERROR_NUMBER to 598. An error message is also displayed: “Insufficient privileges enabled to complete specified action.”
Global sections can be deleted with the CANCEL option in the USE GS statement.
USE NO GS [ \\ [gs_name] [CANCEL] \\ ]
The CANCEL option does a number of operations:
Un-maps a global section (GS) from the user’s process virtual memory;
Subtracts 1 from the system’s “reference count” of a shared global section;
Marks a permanent (group or system-wide) GS for deletion.
NOTES: If other users have the GS mapped into their virtual address space, it will NOT be removed from the system. All reference counts must drop to zero before a GS will be deleted.
To display the state of the actual global sections, one MUST use the INSTALL program in “command” mode procedure:
$ INSTALL :== $SYS$SYSTEM:INSTALL/COMMAND_MODE(equate command)
$ INSTALL (invoke Equated Command)
INSTALL> LIST/GLOBAL (list from Install mode)
Group Global Sections are listed after the system-wide Global Sections. The “LIST/GLOBAL” command can be used by even a non-privileged user.
PURPOSE: Code Segments provide users with a method of defining segments of DBL objects that can be shared by two or more objects. Code Segments can define codes to be shared in SD’s, CM’s, PM’s, GS’s, DI’s, and ID’s. In this way, users can share statements to help manage their development projects. Code Segments are added to a DBL object by using the INCLUDE Statement.
Statements can be designed once, and INCLUDEd wherever needed. There is no syntax checking when a Code Segment is DEFINEd, so a Code Segment does not have to be a “complete” frame of executable code but rather can be an annotated fragment of code. The INCLUDEd Code Segments statements can replace the INCLUDE statement by using the COMPOSE command to aid debugging the application.
See the COMPOSE command documentation for further discussion of this feature.
A Code Segment is DEFINEd in the same way as any other ACCENT R object. Within one, Code Segment there can be several separate segments that can be included individually.
DEFINE CS name [IN DBL dbl_name]
|
name |
is the user-assigned name of the CS being defined. |
|
[IN DBL dbl_name] |
is used to define the CS in the specified DBL. |
*DEFINE CS PAY_CALC
--10 SEGMENT PAY_FIELDS
--20 AMOUNT, N, 8, 2
--30 HOURS, N, 4, 2
--40 CODE, C, 2
--SAVE
INCLUDE PAY_FIELD FROM CS PAY_CALC
Now you can use the INCLUDE statement to add statement 20 thru 40 to, say, a Schema Definition.
The INCLUDE statement is used to add lines from a Code Segment. Also, arguments may be placed in Code Segment, and the values for those arguments specified when the segment is included.
A Code Segment has the following general form:
SEGMENT segment_name.1
…
(ACCENT R statements)
SEGMENT segment_name.2
…
(ACCENT R statements)
Note that you can place as many different SEGMENTs as needed within one Code Segment and that each SEGMENT can be called separately. Typically, all segments that are logically related will be placed in the same Code Segment. The INCLUDE statement may be placed within a segment of code.
A Code Segment can have 36 replacement arguments which are specified in the INCLUDE statement. This lets you generalize the Code Segment so it can be used in many different situations. Replacement arguments within the Code Segment are defined with the following statement:
$ARG_n (and) $ARG_A through $ARG_Z
|
n |
is a digit (0 through 9) that corresponds to the sequence of the replacement arguments given in the INCLUDE statement. A through Z may be upper or lower case ($ARG_A is equivalent to $ARG_a). |
Code Segment names are specified in the INCLUDE statement. Within one Code Segment, there can be several different segments, which can be individually, INCLUDEd. You place an INCLUDE statement in an object where you want the lines of that segment. When you SAVE the object, ACCENT R will compile the lines of the segments in the compiled code.
The syntax of the INCLUDE statement is:
INCLUDE segment_name FROM CS cs_name [IN DBL dbl_name] [WITH \\argument\\]
|
argument |
is a list of string constants which are used to replace the arguments in the INCLUDEd segment. You can specify up to a maximum of 36 arguments. You must specify the arguments in numerical order ($ARG_0, $ARG_1, and so on). |
The INCLUDE statement is treated as one statement when you are stepping through a Process Module using PM DEBUG. Since the statements of a Code Segment are represented by only one line number, you can only break at the beginning of a Code Segment. If you attempt to step through the code segment, PM DEBUG executes the statements of the segment and breaks at the next Process Module statement after the INCLUDE statement. The Code Segments contained within a Process Modules may be actually inserted with the COMPOSE command.
The Code Segment shown here, used to calculate compound interest, has two segments. One segment is for the declared fields and the other segment is for the procedure code. The Code Segment has arguments for the annual interest rate, the principal, and the number of days.
*DEF CS INTEREST_CALC
--I
00001 SEGMENT COMPOUND_INTEREST_DECLARE
00002
00003 DAILY_INTEREST_L, N, 9, 5
00004 COMPOUND_RATE_L, N, 9, 5
00005
00006 SEGMENT COMPOUND_INTEREST
00007
00008 ! $ARG_0 is annual interest rate
00009 ! $ARG_1 is principal
00010 ! $ARG_2 is the number of days
00011 ! $ARG_3 is the total interest
00012
00013 $ARG_0 / 360. TO DAILY_INTEREST_L
00014
00015 ( 1 + DAILY_INTEREST_L ) ** $ARG_2 TO COMPOUND_RATE_L
00016
00017 $ARG_1 * ( COMPOUND_RATE_L - 1 ) TO $ARG_3
00018 END
--SAVE
The Code Segment shown above is INCLUDEd in the Process Module below. There is an INCLUDE statement for the segment that has the locally required declared field, and an INCLUDE statement for the segment with the procedure code in the DETAIL SECTION. The values for the arguments are specified with the name of fields that are entered by the user of the Process Module.
*DEF PM DAILY_INTEREST
--I
00001 DECLARE SECTION
00002
00003 ANNUAL_INTEREST, N, 7, 2
00004 INTEREST, N, 9, 2
00005 NO_OF_DAYS, I, MAX
00006 PRINCIPAL, N, 9, 2
00007
00008 INCLUDE COMPOUND_INTEREST_DECLARE FROM CS INTEREST_CALC
00009
00010 DETAIL SECTION
00011
00012 TYPE@CR,“This program calculates interest compounded daily”, NOCR
00013 TYPE @CR, @CR, “Enter the number of days: “, NOCR
00014 ACCEPT NO OF DAYS
00015 TYPE @CR, “Enter the amount: “, NOCR
00016 ACCEPT PRINCIPAL
00017 TYPE@CR, “Enter the annual interest (such as 13.25):" “,NOCR
00018 ACCEPT ANNUAL INTEREST
00019 ANNUAL_INTEREST / 100 TO ANNUAL_INTEREST
00020
00021 INCLUDE COMPOUND INTEREST FROM CS INTEREST_CALC WITH&
WITH ‘ANNUAL INTEREST’, ‘PRINCIPAL’, ‘NO_OF_DAYS’, ‘INTEREST’
00022 TYPE@CR, "Total compounded interest is:", INTEREST
00023 "$$$,$$$,$$$.$$"
00024 END
--SAVE
Next, the Process Module is executed.
*USE PM DAILY_INTEREST
This program calculates interest compounded daily.
Enter the number of days: 360
Enter the amount: 1000
Enter the annual interest (such as 13.25): 8
Total compounded interest is: $83.2
![]()
![]()